
Extras din proiect
Aceasta lucrare are ca scop analiza unui set de date şi elaborarea modelului de regresie multiplă, pentru acesta utilizând aplicaţia Excel din Microsoft Office şi formularea concluziilor care se pot determina pe baza outputului din Exel.
Pentru studiul modelului de regresie multiplă se va analiza dependenţa preţului mediu al caselor din suburbiile oraşului Boston (mii dolari) în funcţie de alţi 4 factori independenţi – numărul mediu de camere, procentul caselor construite până în anul 1940, denumit generic „Vechime”, indicele de accesibilitate la nodurile magistrale, indicele e criminalitate aferent regiunilor respective. Datele sunt colectate de pe urma unor observaţii efectuate în anul 1993.
Vom reprezenta datele obţinute în tabelul de mai jos:
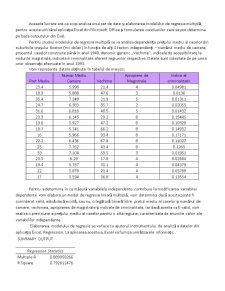
Pret Mediu Numar Mediu Camere Vechime Apropiere de Magistrale Indice al criminalitatii
23.4 5.998 21.4 4 0.04981
18.9 5.888 47.6 3 0.0136
35.4 7.249 21.9 5 0.01311
24.7 6.383 35.7 2 0.02055
31.6 6.816 40.5 5 0.01432
23.3 6.145 29.2 8 0.15445
19.6 5.927 47.2 8 0.10328
18.7 5.741 66.2 8 0.14932
16 5.966 93.4 8 0.17171
22.2 6.456 67.8 8 0.11027
25 7.762 43.4 8 0.1265
33 7.104 59.5 3 0.01951
23.5 6.29 17.8 4 0.03584
19.4 5.787 31.1 4 0.04379
22 5.878 21.4 4 0.05789
17 5.594 36.8 4 0.13554
Pentru a determina în ce măsură variabilele independente contribuie la modificarea variabilei dependente vom elabora un model de regresie liniară multiplă, vom determina dacă acesta poate fi considerat valid, adică dacă există, sau nu, o legătură liniară între pretul mediu al caselor şi numărul de camere, vechimea, apropierea de magistrale şi indicele de criminalitate, iar dacă acesta va fi valid, vom realiza o previziune a preţului mediu al caselor pentru o alta regiune, caracterizata de anumite valori ale variabililor independente..
Elaborarea modelului de regresie se va face cu ajutorul instrumentului de analiză a datelor din aplicaţia Excel, Regression. La aplicarea acestuia, Excel va furniza următoarele informaţii:
SUMMARY OUTPUT
Regression Statistics
Multiple R 0.889950266
R Square 0.792011476
Adjusted R Square 0.716379286
Standard Error 3.011171422
Observations 16
ANOVA
df SS MS F Significance F
Regression 4 379.8007 94.95017208 10.47188336 0.0009507
Residual 11 99.73869 9.067153334
Total 15 479.5394
Coefficients Standard Error t Stat P-value Lower 95% Upper 95%
Intercept -10.45272162 9.002511 -1.161089559 0.270182315 -30.267115 9.36167166
Cam 5.832170925 1.484007 3.930014609 0.002352016 2.5658926 9.09844928
vechime -0.029532572 0.044049 -0.670442454 0.516404667 -0.1264846 0.06741945
magistrale 0.351277643 0.671253 0.52331619 0.611133957 -1.1261406 1.82869587
Crim -47.65397975 26.8946 -1.771879113 0.10407666 -106.84859 11.5406354
RESIDUAL OUTPUT
Observation Predicted pret Residuals
1 22.92810839 0.471892
2 22.88708916 -3.98709
3 32.30956663 3.090433
4 25.44297858 -0.74298
5 29.17726946 2.422731
6 19.97368158 3.326318
7 20.60913617 -1.00914
8 16.76924428 1.930756
9 16.21122416 -0.21122
10 22.75288228 -0.55288
11 30.31686818 -5.31687
12 29.34593638 3.654064
13 25.40314566 -1.90315
14 21.69793133 -2.29793
15 21.84320372 0.156796
16 16.03173404 0.968266
Analiza datelor furnizate de Excel, permite să formulăm un şir de concluzii, fiecare tabel având o anumită putere informativă.
Datele din primul tabel demonstrează că intensitatea legăturii dintre variabilele analizate este puternica, fiind exprimată de indicatorul Multiple R= 0.88, foarte aproapiat de maximum posibil 1. Conform R Square, varianţa variabilei Pret este explicată de varianţa variabilelor numărul de camere, vechimea, apropierea de magistrale şi indicele de criminalitate în proporţie de 79%, de unde rezultă că variabilele independene sunt factori care influeanţeaza puternic Pretul.
Preview document






Conținut arhivă zip
- Crearea si Testarea Modelului de Regresie Multipla cu Ajutorul Aplicatiei Excel.doc
Alții au mai descărcat și

Capitolul 1 Bazele teoretico metodologice ale Analizei economico financiare 1.1 Definirea analizei economico financiare Analiza – ca metodă a...

Obiectivele prelegerii Din studiul acestui material didactic vei avea cunoștințe despre: q Ce este econometrie q Un scurt istoric al apariției...

ANALIZA ECONOMETRICĂ A ACȚIUNILOR UNEI FIRME LA BURSĂ 1.Prezentarea problemei Într-o economie de piață, investitorii financiari sunt permanent...

Introducere Sistemele informatice de marketing reprezinta instrumente manageriale utilizate pentru obtinerea informatiei de marketing, absolut...

1. Notiuni de sistem de operare. Ansamblu de programe ce asigura exploatarea eficienta a calculatorului se numeste sistem de operare. Un sistem de...

INTRODUCERE O societate informaţională este o societate în care crearea, distribuirea, utilizarea, integrarea şi manipularea informaţiilor...

OBIECTIVE Cursul de Metodologia cercetarii stiintifice economice are menirea de a contribui la formarea rapida, în decursul unui singur...

SPSS PREZENTARE GENERALĂ SPSS (Statistical Package for the Social Sciences) este un pachet de programe specializat în analiza statistică a...