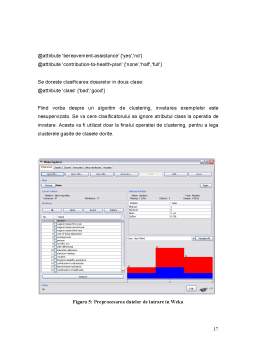
Extras din proiect
1. Introducere
Exploatarea datelor, cunoscuta mai degraba ca „data mining”, este procesul de sortare a unor cantitati mari de date si de extragere a informatiilor relevante din acestea. Termenul este utilizat de obicei de organizatiile ce se ocupa cu prelucrarea informatiilor companiilor si de analistii financiari, dar este folosit din ce în ce mai mult si în domeniul stiintific cu referire la extragerea informatiilor din volumuri mari de date generate de metode experimentale moderne. In relatie cu planificarea resurselor economice, termenul se identifica cu analiza statistica si logica a unor mari volume de date despre tranzactii, în cautarea unor sabloane care pot ajuta procesul de luare a deciziilor
Procesul de data mining implica in general patru clase distincte de actiuni:
• Clasificarea – aranjarea datelor in grupuri predefinite; exemple de algoritmi: invatarea prin arbori de decizie, retele neuronale, clasificare bayesiana, etc.
• Gruparea („clustering”) – similara cu clasificarea, insa fara grupuri predefinite; algoritmul va incerca sa grupeze la un loc articole similare.
• Regresia – cautarea unei functii care modeleaza cat mai fidel datele.
• Invatarea bazata pe reguli de asociere – se cauta relatii intre variabile; exemplu de utilizare: analiza cosurilor de produse, in scopul determinarii obiceiurilor consumatorului.
Procesul de analiza a clusterelor (clustering) se refera la repartizarea unei multimi de observatii in submultimi denumite clustere, cu proprietatea ca elementele ce apartin aceluiasi cluster prezinta similitudini in baza unor anumite criterii. Clusteringul constituie o metoda de invatare nesupervizata, tip de problema ce urmareste determinarea modului in care sunt organizate datele. Acest tip de invatare se deosebeste de metodele de invatare supervizata sau invatare prin recompensa prin faptul ca agentului de invatare ii sunt furnizate doar exemple neclasificate.
2. Clasificarea algoritmilor de clustering
Majoritatea algoritmilor de clustering se clasitica in doua mari categorii: algoritmi ierarhici si algoritmi partitionali. In cazul algoritmilor ierarhici, clusterele sunt determinate succesiv, utilizand clusterele formate la pasii anteriori. Algoritmii partitionali determina toate clusterele in paralel. Exista si alte metode de clustering, ce nu se incadreaza in aceste clase, dintre care amintim clasa algoritmilor de clustering spectral, ce utilizeaza o matrice de similaritate pentru a reduce numarul de dimensiuni (variabile) din problema.
In clasa algoritmilor ierarhici de clustering se idetifica doua tipuri de strategii:
• Clustering algomerativ – aceasta este o strategie de tip „bottom-up”, ce porneste de la o stare in care toate elementele reprezinta clustere individuale si fuzioneaza succesiv aceste clustere pana obtine schema finala.
• Clustering diviziv – aceasta este o strategie de tip „top-down”, cu o stare initiala caracterizata de un singur cluster, format din multimea tuturor elementelor si progresand prin divizarea sa in clustere dn ce in ce mai restranse.
Clusteringul ierarhic construieste (in cazul strategiilor aglomerative) sau segmenteaza (in cazul strategiilor divizive) o ierarhie de clustere. Reprezentarea clasica a unei astfel de ierarhii este in forma de arbore si poarta numele de dendrograma. Radacina dendrogramei consta dintr-un singur cluster continand toate elementele, iar frunzele corespund elementelor individuale. Algoritmii aglomerativi vor incepe la nivelul frunzelor, fuzionand treptat clustere, in timp ce algoritmii divizivi pornesc explorarea arborelui de la radacina si segmenteaza recursiv clustere.
Similaritatea intre elemente se poate determina pe baza oricaror criterii valide, iar pe baza acestor criterii algoritmul poate lua decizia fuzionarii sau divizarii de clustere.
Fie exemplul de mai jos, in care consideram distanta euclidiana dintre elemente drept criteriu de formare a clusterelor.
Preview document






















Conținut arhivă zip
- COBWEB.doc
- labor.arff
- labor_new.arff
- result labor.txt
- result labor new.txt
Alții au mai descărcat și

1. Introducere Lingvistica computaţională este o disciplină centrată în jurul folosirii calculatorului pentru a procesa sau a produce texte în...

Baze de date multimedia Definirea conceptelor. Aplicatii. Data base - baza de date - este un grup de fisiere în care este înregistrata o multime...

Aplicatii client server Studiu de caz- Solutie de gestiune a Resurselor Umane si Salarizarii Solutiile de gestiune economica Mobius, sunt...

RETELE WIRELESS Introducere Cresterea popularitatii retelelor wireless a determinat o scadere rapida a pretului echipamentelor wireless...

“Feedback-ul este ceea ce lipsea din stiinta, in afara lui Newton”, spunea omul de stiinta britanic Steve Grand. “Noi credeam ca este un fenomen...

Programul realizeaza determinarea procesului de incalzire ,respectiv racire intr-o camera si a timpului (maxim respectiv minim) in functie de trei...

I. INTRODUCERE Dezvoltarea ştiinţei a demonstrat că cele mai spectaculoase progrese se obţin prin cercetare pluridisciplinară, situată la graniţa...

Scheme Hidraulice Prima schema Hidraulica este in figura 1: Figura 1 A doua schema hidraulica este in figura 2 : Figura 2 A treia schema...