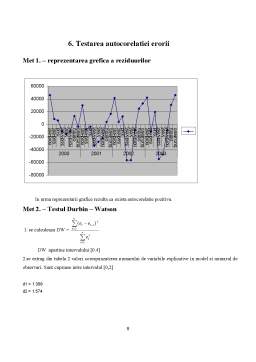
Extras din proiect
Econometria este acea ramura a economiei in care ipotezele apar sub forma expresiilor matematice, iar seriile de date sunt colectate empiric si apoi supuse testelor statistice. Una din principalele preocupari ale neoclasicismului modern consta in constituirea de modele econometrice la nivel micro si macroeconomic.
Modelele econometrice sunt constituite din ecuatii care pun in evidenta relatiile dintre diferitele variabile economice.
Reprezentarile econometrice, spre deosebire de modelele economice care explica structura fenomenului sau procesului economic de pe pozitia teoriei economice, au intotdeauna o finalitate practica, operationala, ele devenind instrumente de control si dirijare, de simulare si de previziune a fenomenelor economice.
Datele utilizate pentru construirea urmatorului model econometric sunt date reale obtinute de la institutul national de statistica.
Modelul este realizat pe o perioada de patru ani in cele opt regiuni din Romania si anume: nord-est, sud-est, sud, sud-vest, vest, nord-vest, centru si bucuresti.
Din regiunea de nord-vest fac parte urmaroarele judete: Bacau, Botosani, Iasi, Neamt, Suceava si Vaslui. Din regiunea de sud-est fac parte: Braila, Buzau, Constanta, Galati, Tulcea, Vrancea. In sud sunt incluse urmatoarele judete: Arges, Calarasi, Dambovita, Giurgiu, Ialomita, Prahova si Teleorman. Din regiunea de sud-vest fac parte: Dolj, Gorj, Mehedinti, Olt, Valcea. Judetele Arad, Caras-Severin, Hunedoara si Timis apartin regiunii de vest. In nord-vest sunt incluse judetele Bihor, Bistrita-Nasaud, Cluj, Maramures, Satu Mare, Salaj. In centru sunt judetele: Alba, Brasov, Covasna, Harghita, Mures, Sibiu. Iar Ilfov si Municipiul Bucuresti sunt incluse in regiunea Bucuresti.
Variabila de explicat (Y) este produsul intern brut pe regiuni in miliarde ROL.
Variabilele explicative (X) sunt:
• X1 – rata somajului pe regiuni in procente.
• X2 – numarul de locuitori din fiecare regiune
• X3 – castigul salarial nominal mediu net lunar in ROL pe salariat
• X4 – numarul de orase si municipii din fiecare regiune
Pentru a vedea ce influenta au variabilele explicative asupra variabilei de explicat am aplicat urmatoarele teste statistice: Student, Fisher, Chow, Farrar-Glauber, Selectarea variabilelor explicative, Variabila Dummy, Durbin-Watson si Goldfeld-Quandt.
1. Testul Student
= + x + x + x + x
y = a +a x +a x +a x +a x
Testul student sau testul de semnificatie individuala presupune parcurgerea urmatorilor pasi:
1.se stabilesc ipotezele:
H0: a =0
H1: a ≠0
2.se afla t* ( ratia student)
3.se extrage din tabela legii de distributie Student o valoare notata t (t teoretic)
4.se compara ratia Student cu valoarea luata din tabel.
Daca t* ≤ t - se accepta H0 - aceasta inseamna ca cu probabilitatea de 1-α variabila explicativa nu influenteaza semnificativ variabila de explicat.
Daca t* > t - se accepta H1 - - aceasta inseamna ca cu probabilitatea de 1-α variabila explicativa influenteaza semnificativ variabila de explicat.
In urma aplicarii testul Student (anexa 1) am obtinut urmatoarele rezultate:
a1 - t* = 4.75621 > t teoretic - se accepta H1 k = 4
a2 - t* = 4.2503996 > t teoretic - se accepta H1 n-k-1 = 27
a3 - t* = 7.6927652 > t teoretic - se accepta H1
a4 - t* = 0.95428 < t teoretic - se accepta H0
t = 2.0518305
Variabilele explicative X1,X2,X3 influenteaza semnificativ variabila de explicat.
Variabila explicativa X4 nu influenteaza semnificativ variabila de explicat si de aceea trebuie scoasa din model.
Preview document












Conținut arhivă zip
- Econometrie.doc
Te-ar putea interesa și

INTRODUCERE Modelele econometrice analizează calitatea şi cantitatea proceselor economice şi evoluţia lor. Econometria prin caracterul său general...

INTRODUCERE Studierea mecanismelor şi a politicilor de reglare a cererii şi ofertei de forţa de muncă în perioada de tranziţie la economia de...

1. Obiectivele Econometriei Econometria are ca obiect cunoaşterea mecanismelor de desfăşurare a proceselor economice, descrise de seriile de date...

1. SCURTĂ DESCRIERE A COLUMBIEI 1.1. ORGANIZARE TERITORIALĂ Columbia (spaniolă Colombia), oficial Republica Columbia este o țară din partea de...

Introducere in econometrie Dezvoltarea rapida a econometriei a generat formularea mai multor definitii cu privire la domeniul acestei discipline...

1. Introducere – prezentarea variabilelor modelate Numărul salariaţilor din economie (mii pers.) În documentul realizat de Comisia Naţională...

CAPITOLUL I Piaţa asigurărilor de viaţă 1.1. Caracteristici generale ale pieţei asigurărilor Operaţiunile de asigurare realizate pe baze...

1 Analiza comerțului exterior folosind analiza econometrică 1.1 Culegerea datelor 2 Analiza modelului econometric folosind pachete de programe...