Extras din proiect
PROIECT 2: Aplicaţie numerică la una dintre următoarele doua teme: Analiza Cluster (Recunoaştere Nesupervizată a Formelor) sau Analiza Discriminantă (Recunoaştere Supervizată a Formelor);
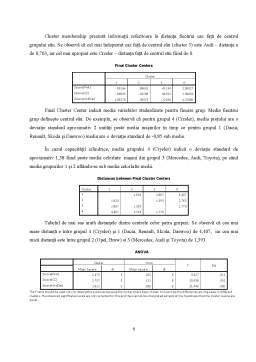
REZOLVARE: Imaginăm o situaţie având variabile astfel: Marca maşinii (Marca), preţul de achiziţie al maşinii (Pret), capacitatea cilindrică a maşinii (CC), dacă se cumpără având sau nu asigurare Casco (Casco), consumul mediu al maşinii (Consum), gradul de îndatorare al clientului la achiziţionarea maşinii prin leasing (GrdDat).
Observăm că variabilele pe care le folosim sunt măsurate în scale diferite. De aceea trebuie să folosim procedura Analyze Descriptive Statistics Descriptives pentru a standardiza variabilele cu ajutorul procedurii Z (astfel valoarile pentru fiecare variabilă sunt ”re-scalate” pentru a avea media 0 si deviaţia standard de 1).
Selectăm variabilele care vor fi standardizate (preţ, CC, GrdDat) şi bifarea opţiunii Save standardized values as variables va adăuga, în baza de date de lucru, valorile standardizate ale variabilelor (scorurile z). Astfel se va forma o nouă bază de date adăugându-i-se alte şase variabile standardizate de tipul „znume variabilă”. Pentru gruparea cazurilor în funcţie de Cluster Analyze K-means alegem din meniu Analyze Classify K-Means Cluster
Din meniul principal alegem pentru grupare, cele trei variabile standardizate (Zpret: preţ, ZCC: CC şi ZGrdDat: GrdDat), în căsuţa Label Cases by alegem variabila Marca. La Number of Cluster, este specificat numărul de grupuri = 2; iar la Method bifăm Iterate and classify pentru a repeta şi clasifica cazurile. Din submeniul Iterate alegem 10, acesta fiind numărul maxim de repetări ale algoritmului.
Maximum iterations - limitează numărul de repetari în algoritmul K-Means. Repetarea se opreşte după acest număr de repetari chiar dacă criteriul de convergenţă nu este satisfacut. Acest număr poate fi între 1 si 999.
Convergence criterion - se determină atunci când încetează repetarea. Reprezintă o proporţie a distanţei minime între centrii clusterelor iniţiale, deci trebuie să fie cuprins între 0 şi 1. Use running means - permite să se solicite reactualizarea centrelor clusterilor după ce a fost repartizat fiecare caz. Dacă nu se selectează această opţiune, noi centre sunt calculate după ce au fost repartizate toate cazurile. Din submeniul Save selectăm, Cluster membership - crează o variabilă nouă indicând numarul final de clustere pentru fiecare caz. (aceasta ia valori de la 1 până la nr de grupuri nou create). „Distance from cluster center” – bifarea opţiunii determină crearea unei noi variabile indicând distanţa euclidiana dintre fiecare caz si centrul sau de clasificare.
Preview document









Conținut arhivă zip
- K-MEANS.pdf
- K-MEANS.sav
- K-MEANS.spo
Alții au mai descărcat și

DEFINITIE: SERIA CRONOLOGICA este un sir ordonat de valori ale unei variabile aferente unor momente sau perioade de timp succesive. Exista...

Düfa ROMÂNIA SRL este una dintre cele mai dinamice companii ce opereaza pe piata de lacuri si vopsele din România. Compania a fost fondata în anul...

Spitalul de Boli Infectioase „Sf.Cuvioasa Parascheva „ este situat in partea de nord a orasului Galati pe strada Traian nr.393 ,în cartierul numit...

Q1+Q2. La aceste intrebari filtru, nici unul dintre cei 1000 de respondenti nu a fost eliminat Valoarea modala (Mo – cea mai mare frecventa de...
Obiectul principal în evolutia repartitiei bidimensionale îl reprezinta determinarea legaturii statistice dintre aceste doua variabile. În orice...
Te-ar putea interesa și

I.Descrierea datelor Analiza datelor are ca obiectiv principal extragerea informatiei relevante , semnificative care este continuta in informatia...

i. Obiectivele lucrĂrii Lucrarea de faţă, intitulată “Implicaţii ale inteligenţei artificiale în dezvoltarea proceselor de afaceri”, doreşte să...

Definirea si comentarea conceptelor si descriptorilor manageriali Managementul performant opereaza cu urmatoarele concepte si descriptori...

1.Inteligenta Artificiala Generalitati Scopul Inteligentei Artificiale (AI) este de a dezvolta algoritmi sau metode pentru sistemele de calcul,...

1. Care este diferenta intre un semnal continuu si un semnal continuu cuantificat? In functie de evolutia temporala semnalele se clasifica in...

Reprezentarea cunoaşterii prin cadre şi scenarii Reprezentarea cunoaşterii prin cadre Se ştie că oamenii nu interpretează noile situaţii...

1.1. Prelucrarea de imagini - principii generale. 1.2. Teoria recunoasterii formelor - generalitati. 1.2.1. Principii generale. 1.2.2. Strategii...