Extras din proiect
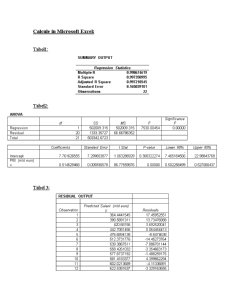
Interpretare rezultate din tabelul SUMMARY OUTPUT:
- R= 0.99867 arată că între valoarea salariilor şi valoarea PIB-ului din Franta există o legătură puternică.
- R2 = 0.99735 arată că 99% din variaţia salariilor din Franta este explicată de PIB-ul Frantei.
- Abaterea medie patratica a erorilor = 8.165. Reprezinta eroarea punctelor fata de dreapta de regresie. Functia de regresie este reprezentativa.
- Nr de observatii: 22;
Pentru aceasta aplicatie putem concluziona ca modelul de regresie liniara simpla este bun.
Interpretare rezultate din tabelul ANOVA:
Tabelul 2, se referă la descompunerea varianţei totale (SST) a variabilei dependente în două componente: varianţa explicată prin regresie (SSR) şi varianţa neexplicată (SSU) sau varianţa reziduală Aici identificăm şi gradele de libertate asociate descompunerii, mai precis, dacă avem k regresori în model şi n observaţii, avem egalitatea În această casetă există două celule importante la care trebuie să fim atenţi, şi anume: F şi Significance F. Valorile din aceste celule ne dau elemente importante ce stau la baza validării modelului de regresie (în totalitatea sa). Ele ne furnizează informaţii privind valoarea calculată a statisticii test F şi erorii pe care putem s-o facem când respingem modelului de regresie ca fiind neadecvat. Regula de decizie privind acceptarea modelului este: valori mari pentru statistica test
F şi valori mici pentru Significance F. Significance F reprezinta valoarea erorii pe care o facem prin respingerea ipotezei nule cand de fapt ea este adevarata.
În acest tabel este calculat testul F pentru validarea modelului de regresie. Întrucât F= 7530.004 , iar Significance F (pragul de semnificatie) este 0.0000 (valoare mai mica de 0.05) atunci modelul de regresie construit este valid şi poate fi utilizat pentru analiza dependenţei dintre salariile si PIB-ul Frantei.
Tabelul 2 ne oferă informaţii despre valorile estimate ale coeficienţilor modelului de regresie în coloana Coefficients, erorile standard ale coeficienţilor în coloana Standard Error, elemente pentru aplicarea testului de semnificaţie t-Student pentru fiecare coeficient (coloanele t Stat şi P-value.). Deci, valoarea din coloana t-Stat se obtine impartind pentru fiecare estimator al modelului, valoarea estimatiei la eroarea standard a estimatorului şi astfel obtinem valoarea calculata a testului t pentru fiecare estimator al modelului. Aceasta valoarea calculata se compara cu valoarea tabelara preluata din tabelul repartitiei Student.
Intercept este termenul liber, deci coeficientul este 7.76162. Termenul liber este punctul în care variabila explicativă (factorială) este 0. Deci salariile din Franta, dacă PIB-ul este 0. Deoarece = 1.06328 iar pragul de semnificaţie P-value este 0.3003 >0,05 înseamnă că acest coeficient este nesemnificativ. De altfel faptul că limita inferioară a intervalului de încredere (-7.46518 22.9884) pentru acest parametru este negativă, iar limita superioară este pozitivă arată că parametrul din colectivitatea generală este aproximativ zero.
Coeficientul este 0.51462 , ceea ce însemnă că la cresterea PIB-ului cu 1 mld euro, salariile vor creste cu 0.51462 mld euro. Deoarece = 86.7755 iar pragul de semnificaţie P-value este 0,00000< 0,05 înseamnă că acest coeficient este semnificativ. Intervalul de încredere pentru acest parametru este 0.50225 0.5270.
2.Regresie bifactoriala
In prima parte a proiectului am analizat influenta Pib-ului din Franta asupra salariilor din aceasta tara. In urmatoarea etapa voi adauga inca o variabila independenta : impozitele pe produse ale Frantei in aceeasi perioada pentru a vedea daca modelul este valid.
Preview document















Conținut arhivă zip
- Influenta PIB si a Impozitelor asupra Salariilor.doc
Alții au mai descărcat și

Introducere Modelul clasic de regresie liniară reprezintă una dintre tehnicile statistice cele mai versatile şi mai des utilizate în analiza...

1. Datele problemei: Indicele dezvoltării umane (IDU) este o masura comparativa a sperantei de viata, a nivelului de educatie si nivelului de...

Indicele Dezvoltarii Umane (IDU) cuprinde trei elemente de baza: longevitatea, nivelul de educatie si standardul de viata. Longevitatea este...

Analiza macro-mediului intreprinderii Studiul macro-mediului intreprinderii permite depasirea orizontului mediului concurential deoarece...

1. Abordarea clasica – Sa presupunem ca dispunem de informatii privind venitul disponibil si cererea de consum la nivelul unei economii nationale,...

Estimatorii metodei celor mai mici pătrate în prezenţa autocorelaţiei În cazul autocorelaţiei erorilor, matricea de varianţă-covarianţă a...
Reforme institutionale si politice in U.E. inaintea procesului de largire. Actuala forma de organizare ce cuprinde 15 tari membre nu mai...
Te-ar putea interesa și

INTRODUCERE Bugetul a apărut şi s-a dezvoltat de-a lungul ultimelor decenii, ca principal instrument de proiecţie a veniturilor şi cheltuielilor...

1.1. Conceptul de politică bugetară Politica bugetară reprezintă expresia alegerilor bugetare realizate de un centru de decizie publică (local,...

INTRODUCEREA ŞI MOTIVAŢIA TEMEI Viitorul oricărui stat modern este de neconceput fără un sistem fiscal performant prin randament şi...

1.1. Fundamentarea teoretica a statului modern si aparitia primelor conceptii economice Dupa prabusirea Imperiului Roman, timp de o mie de ani,...

Cap. 1 Concept şi semnificaţii ale presiunii fiscale Prezenţa fiscalităţii în contextul dezvoltării societăţii se leagă de crearea şi funcţionarea...

1. Politica fiscală: concept, obiective şi rol 1.1 Conceptul de politică fiscală În abordarea politicii fiscale trebuie stabilit mai întâi,...

STRATEGII SI POLITICI ECONOMICE. Acestea se elaboreaza pe baza studiilor prospective si a prognozelor. Strategia economica e un ansamblu de...

PREVIZIONAREA CREŞTERII ECONOMICE I. Noţiuni şi corelaţii avute în vedere în activitatea de previzionare. Creşterea economică este un proces...