Extras din proiect
Aspecte teoretice - recapitulare
Analiza de regresie studiază legătura dintre o variabilă dependentă şi una sau mai multe variabile independente, prin intermediul unei ecuaţii de regresie. În cadrul cursului de faţǎ vom discuta doar despre regresia liniarǎ, a cǎrei ecuaţie are forma:
unde:
- y este variabila dependentă (numită şi cauzată sau endogenă);
- x1, , xk sunt variabilele independente (numite şi cauzale sau exogene);
- b0 este aşa-numitul “termen liber”;
- b1, , bk sunt coeficienţii (sau parametrii) de regresie;
- e este numită variabilă reziduală sau de perturbaţie. Apariţia sa în modelele de regresie se datoarează faptului că relaţia dintre variabila dependentă şi cele independente nu este una strictă, deterministă, ci una statistică. Pentru fiecare unitate din eşantion, variabila reziduală se calculează ca diferenţă între valoarea reală (sau observată) a lui y şi cea calculată (sau estimată) prin ecuaţia de regresie de mai sus. Variabila e “colectează” aşadar influenţele tuturor factorilor necunoscuţi sau întâmplători, dificil de estimat, precum şi erorile de măsurare.
Toate variabilele care intervin într-o analizǎ de regresie sunt variabile cantitative (metrice). Dacă existǎ o singură variabilă independentă în model, vorbim de o regresie simplă, iar dacă intervin două sau mai multe variabile independente avem de-a face cu o regresie multiplă.
Rezultatele cele mai importante ale unei analize de regresie sunt:
- coeficienţii (sau parametrii de regresie). Aceştia ne arată cu cât se modifică variabila dependentă în urma modificării cu o unitate a uneia din variabilele independente.
- coeficientul de corelaţie multiplă (notat R2), care ne arată procentajul din variaţia lui y care este “explicat” de influenţa variabilelor independente. De pildă, o valoare a lui R2 de 0.90 ne indică faptul că evoluţia variabilei y este determinatǎ în proporţie de 90% de variabilele independente x1, , xk, iar restul de 10% se explică prin alte influenţe, neluate în considerare în model.
- valoarea testului F. Acest test verificǎ existenţa unei dependenţe liniare între variabila y şi variabilele independente. În cazul în care testul F este nesemnificativ, legǎtura ar putea sǎ nu fie liniarǎ.
- valoarea testelor de semnificaţie pentru coeficienţii de regresie. Dacă parametrul de regresie al uneia din variabilele independente nu diferă semnificativ de 0, este posibil ca variabila respectivă să fie redundantă.
Într-o serie de situaţii particulare, pot fi introduse în modelel de regresie şi anumite variabile calitative (nemetrice), şi anume variabilele de tip dummy. O variabilă dummy este o variabilă care poate lua doar două valori (da/nu, bărbaţi/femei, mediu urban/mediu rural etc.), notate convenţional cu 1 şi 0. Desigur, ar putea fi folosite oricare alte cifre pentru a nota valorile unei variabile dummy, dar acest lucru ar duce la o serie de inconveniente. O asemenea variabilă poate fi utilizată într-o ecuaţie de regresie în acelaşi mod ca o variabilǎ cantitativǎ.
Analiza de regresie în SPSS
În exemplul de analiză de regresie ce urmeazǎ vom folosi tot baza de date Employee data.sav. Ca variabilă dependentă vom considera salariul actual (salary), iar ca variabile independente salariul de început (salbegin), vechimea în bancă (jobtime) şi nivelul de educaţie (educ). Pentru a rula analiza de regresie vom apela comanda:
Analyze > Regression > Linear
În câmpul “Dependent” introducem variabila salary, iar în câmpul “Independent(s)” introducem cele trei variabile independente. Apăsăm OK pentru a rula analiza.
Iată tabelele de output care ne interesează:
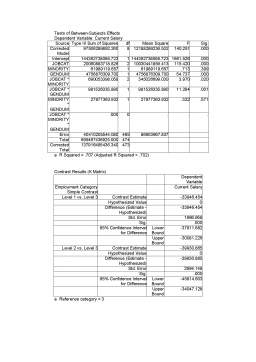
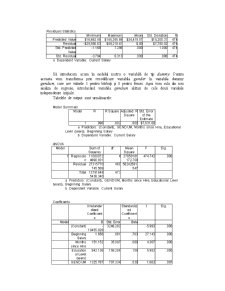
Model Summary
Model R R Square Adjusted R Square Std. Error of the Estimate
1 895 801 800 $7,646.00
a Predictors: (Constant), Educational Level (years),
Months since Hire, Beginning Salary
b Dependent Variable: Current Salary
În acest tabel ne este prezentat un sumar al analizei. Cea mai interesantă pentru noi este penultima coloană, unde putem vedea coeficientul de corelaţie multiplă, egal cu 0.80 pentru această analiză. Aceasta înseamnă că salariul curent al unui lucrător este determinat în proporţie de 80% de cele trei variabile independente şi în proporţie de 20% de alte influenţe, neluate în calcul aici.
ANOVA
Model Sum of Squares df Mean Square F Sig.
1 Regression 110439694339.523 3 36813231446.508 629.703 000
Residual 27476801096.817 470 58461278.929
Total 137916495436.340 473
a Predictors: (Constant), Educational Level (years), Months since Hire, Beginning Salary
b Dependent Variable: Current Salary
Acest tabel ne prezintă rezultatele analizei ANOVA pentru modelul nostru de regresie. Dupǎ cum spuneam în secţiunea anterioara, testul F ne aratǎ dacă ipoteza relaţiei liniare între variabilele noastre este corectă. Regula de decizie este simplă: ipoteza relaţiei liniare este corectă dacă valoarea factorului “Sig.” din ultima coloană este mai mică decât nivelul de semnificaţie ales de noi (0.05). În caz contrar, va trebui să luăm în considerare construirea unui alt tip de relaţii (neliniară) între variabilele în cauză.
Preview document




























Conținut arhivă zip
- Analiza de Regresie.doc
Alții au mai descărcat și

Capitolul 1. Descrierea firmei Denumirea firmei: Grupul de firme S.C KOSAROM S.A – Pascani Domeniu de activitate principal : producator in...

3.4. Metodologia auditului sistemelor calitatii Standardul international ISO 10011 stabileste principiile, criteriile, practicile de baza si...

Mediul extern al firmei poate fi impartit in doua mari segmente: - mediul general sau mega-mediul - mediul specific(mediul sarcina);...

WHO and HOW MADE IT POSSIBLE? In order to get where Sicomed has got one has to be very talented, very intelligent an also very patient. The...
Te-ar putea interesa și

CAPITOLUL 1 - INTRODUCERE Problema unui autovehicul ideal apare când clientul se hotărăște să cumpere un astfel de produs după criteriile tehnice...

Introducere Infracţiunea este în general privită, în teoria dreptului penal şi în diferite legislaţii, din două puncte de vedere: fie ca un...

1.1 Definirea problemei Studentii anului 1, învatamânt la distanta, specializarea Economie si Gestiune Financiar Bancara, învatamânt...

Rezumat Introductiv\aBRD Groupe Societe Generale doreste introducerea pe piata a unui nou tip de card VISA Electron care va avea numele CreditStud....

1. Prezentarea temei de cercetare Intr-un moment in care majoritatea activitatilor contemporane se concentreaza catre tehnologizarea maxima a...

1. Prezentarea problemei 1.1. Descrierea fenomenului analizat și a factorilor explicativi considerați Fenomenul analizat este natalitatea....

INTRODUCERE 1. Definirea problemei Colectivitatea cercetată a fost reprezentată de 26 de elevi aflaţi în clasa a XII-a din cadrul unor clase cu...

Capitolul 1. Introducere Acest proiect analizează o bază de date prin intermediul programului de prelucrare de date SPSS. Baza de date analizată...